The Fourth Operation
- tetration from a real perspective -
Introduction · Groping for a Solution · Uniqueness · A Related Problem · Facts About Functions · Asymptotic Power Series · To Proceed · The Original Problem · Computer Program I · Another Path · Computer Program II · Is it Unique? · Bases Other Than e · Review and Complex Numbers · A Zero’th Operation? · Other Terminology and Notation · Afterword
Introduction
Given whole numbers A and B we can add them together to get another whole number,The definition of this operation is simply to count together what A and B count separately.
Then we can define multiplication as repeated addition:| A · B = | A + A + A + ... |
| | B times |
And exponentiation as repeated multiplication:| AB = | A · A · A · ... |
| | B times |
Those are the first, second, and third operations: addition, multiplication, and exponentiation. Presented in this manner a prolonged series of operations comes to mind, each operation iterating the one before. The fourth operation would be (using a subscript to denote the second operand):
We chose the grouping of the tower of A’s so that the exponentiations are done from top to bottom, A to the (A to the (A to the ...)). Any other grouping would collapse, at least in spots, reverting to the third operation, because (X to the X) to the Y equals X to the (X·Y).
The series of operations can be defined recursively on the second operand.Addition:Given.
Multiplication:A
· 1 = A
A
· (B + 1) = A + A
· B
A [n] 1 = A
A [n] (B + 1) = A
[n – 1]
(
A [n] B
)
Historical note: A [n] B when A and B are whole numbers is the same as the function φ(A, B, n – 1) that Wilhelm Ackermann (1896 – 1962) described in a paper of 1928.
Thus we can define a series of operations between positive whole numbers. It is well known how to extend the definition of the first two operations, addition and multiplication, to include all real numbers. The third, exponentiation, can be substantially so extended. The only restriction is that the base, A in AB, be nonnegative; this is necessary to ensure that the operation is well-defined and continuous as the exponent, B, varies.
The problem we investigate here is how to define the fourth operation, AB or A raised to itself B times, for fractional B. What, for example, is A½ or A raised to itself one half times? It might sound like a crazy question but no crazier than asking what is A multiplied by itself one half times. In that case the answer is the square root of A.
For now, it will make some formulas simpler if we consider just the case A = e, the base of the natural logarithms.e0 = 1
e1 = e = 2.71828…
e2 = ee = 15.15426...
e3 = eee = 3814279.10476…
etc.
What ises
when s is not a whole number?
In order to solve the problem we will reformulate the fourth operation in terms of functional iteration, then we can use techniques of functional analysis to try to solve the problem. As well as our own ideas we will use ideas from the paper by G. Szekeres “Fractional iteration of exponentially growing functions” (J. of the Australian Mathematical Soc., vol. 2, 1962) and its addendum (co-authored with K. W. Morris) “Tables of the logarithm of iteration of ex–1,” which relies on his “Regular iteration of real and complex functions” (Acta Math., vol. 100, 1958). Note that Szekeres’ point of view differs from ours in that his primary interest is (see below for definitions) in functions fs(x) as functions of x where s is thought of as a parameter, whereas to us fs(x) = exps(x) is a stepping stone to exps(1) where s is the variable. Jumping ahead, Szekeres states that the second-order coefficient in the power series we call Φ(x) is 1/2 (when f(x) = exp(x) – 1 ) but he fails to prove it or even make it plausible.
The mathematical technique we will need is fairly simple: algebra, calculus of functions of a single variable, and the rudiments of real analysis.
Sometimes we will write “exp” for the exponentiation of e function:exp(x) = ex
and place a subscript on exp to denote the level of its iteration. The functional iterates of exp(x) are closely related to es. First observe thatexp0(x) = x
exp1(x) = exp (x)
exp2(x) = exp (exp (x))
exp3(x) = exp (exp (exp (x)))
etc. Thusexp n (exp m (x) ) = exp n+m (x)
holds for all non-negative integers n and m. Setting x = 1 in expn(x) gives us the fourth operation without the “socket” x:expn(1) = ee...e, n times = en
Our goal is to define the functionexps(x)
for real numbers s, such thatexp 1 (x) = exp (x)
exp s (exp t (x) ) = exp s+t (x)
for real s and t. Thenexps(1)
will answer our original question, what is es, that is, e raised to itself s times.
If that isn’t clear consider the third operation, exponentiation. It is iterated multiplication and can be obtained by iterating the function “mul”:Thus| mul (mul (x)) = e e x | or | mul2(x) = e2 x |
| mul (mul (mul (x))) = e e e x | or | mul3(x) = e3 x |
muls(x) = es x
so thatmuls(1) = es
Iterates of the function mul(x) where x is a sort of socket for the first (viewed from the right) multiplier gives a different way to look at exponentiation.
Groping for a Solution
First we will examine how the third operation, exponentiation, is defined when the exponent is a fraction and see if something analogous can be done for the fourth operation.
Unlike the operations of addition and multiplication, each of which has just one inverse (subtraction and division), exponentiation has two inverses because it is not commutative, the order of the operands matters. GivenX = bp
one operation is required to obtain the base b and another the exponent p. Taking a root gives the baseb = pth root of X = p√ X
and taking a logarithm gives the exponent:p = logarithm (base b) of X = logb X
where contrary to our usage later the subscript b of log does not denote iteration.
Consider the first inverse, the root. Using facts about exponents with which I’ll assume you are familiar, given that we have defined exponentiation when the exponent is an integer we can use the root operation to define it when the exponent is any rational number. In what follows let m and n be integers, n positive, and X a positive real number. Then letX1/n = n√ X
andXm/n = n√ X m
This comports with the definition of exponentiation when m/n is an integer and otherwise obeys the expected behavior of exponentiation. (If you investigate you will see it does this because multiplication is commutative and associative, multiplication doesn’t depend on the order or grouping of its operands.) Then by insisting that exponentiation be continuous we can define it for real s by taking any sequence of rational numbers ri that converges to s as i → ∞ (here the subscript on r is an index, not the fourth operation):lim ri = s
i → ∞
and definingXs = lim X r i
i → ∞
(this is well defined, that is, it does not depend on the sequence, because taking powers and roots are continuous functions).
The trouble with generalizing this procedure (using root, the inverse for the first operand) is that, to repeat, it uses the fact that multiplication is commutative and associative. These two properties give a certain homogeneity to multiplication which allows us to turn a fraction 1/n into an integral root, and a fraction m/n into an integral power of that root. This will not work for the fourth operation.
Now consider the other inverse of exponentiation, the logarithm. Though its basic definition is that it is the exponent there is an interesting theorem which enables us to compute it more directly. Letf (x) = ∫1x 1/t dt
Then for all real x and y(On the right side, in the second integral make the change of variables u = xt .) Thus for any whole number pf (xp) = p f (x)
And then for any whole number qq f (x1/q) = f (x(1/q)q) = f (x)
so thatf (x1/q) = 1/q f (x)
Thus for any rational number rf (xr ) = r f (x)
and since f is continuous (indeed differentiable) this holds for any real number r. Finally, let e be the solution to f (x) = 1 (there is one and only one solution because f (1) = 0 and f (x) increases to infinity). We choose the symbol e advisedly because the solution will turn out to be Euler’s number. Thenf (er ) = r
Thus f (x) is the logarithm for exponentiation using the base e and we have the famous formula for it:
From this we can determine ex as well because it is the inverse of log x. (We write log for the natural logarithm function which in Calculus textbooks is usually written ln .)
Note that the derivative of log x is:a simple function independent of log x and of ex. Thus we can use the known function 1/x to determine the function log x. This contrasts with the derivative of ex , which is ex again.
Though the second procedure (using the logarithm function, the inverse for the second operand) doesn’t generalize to higher operations, for the same reason the first doesn’t, it does furnish an important clue: if one seeks to continuously iterate a function – any function, not just exp – then instead of trying to find it directly, look for the derivative of its inverse – the inverse that gives the “higher” operand. In other words, try to define the derivative of the generalized “logarithm” that counts the number of times the function was applied in its argument.
Uniqueness
The hard part of the problem of defining the fourth operation es isn’t finding a definition it is finding a natural, best definition. There are any number of “low quality” solutions: in the interval 0 ≤ s < 1 setes = any function of s that is one when s is zero
then use the fact thates+1 = ees
to translate the values at 0 ≤ s < 1 to any higher unit interval. In effect, for s ≥ 1 find its integral part n and fractional part t and setes = expn(et)
What is wanted is a condition on our definition of es that makes it the unique best definition.
The problem is analogous to defining the factorial functionn ! = n (n – 1) (n – 2) ... 1
for fractional n. We could define 0 ! = 1 and s ! as anything when s is between 0 and 1, then use(s + 1) ! = s ! (s + 1)
to define it for other values of s. However one particular definition of s! (we omit the details) has two properties that recommend it: (1) it arises by a simple and natural argument, (2) it is the only function defined for s ≥ 0 such that 0 ! = 1, s ! = s (s – 1) !, and that is logarithmically convex. It is also the only such function that is asymptotically equal to a logarithmico-exponential function. Likewise, in trying to define a fourth operation that is the fourth operation we shall look for a purely real variable solution.
A Related Problem
Finding a continuous iterate of ex that is natural and arguably the best is a difficult problem to attack directly, so instead at first we will try to find such an iterate for a slightly different functione(x) = ex – 1
This function has a fixed point, the only one, at zero:e(0) = 0
The continuous iterate of a smooth function with exactly one fixed point can be found by determining its Taylor expansion about the point.
... I knew a man who dropped his latchkey at the door of his house and began looking for it underneath the street light. I asked him why he was looking for it there when he knew very well it was by the door. He replied “Because there isn’t any light by the door.” LOL.
In our case, Froggy, we might find a key to the key where the light is. Perhaps if we solve the continuous iteration problem for e(x) we will be able to use it to solve the problem for exp(x). Now please stay out of the Algorithms section.
Our notation can be confusing in that sometimes e stands for Euler’s number 2.718 ... and sometimes for the function e(x) = exp(x) – 1. The function es(x) iterates the function e(x), yet if we were to write the iterated function without its argument, like this es, it would look like the fourth operation — e^(e^(...^e) ) s times — rather than the sth iterate of e(x). To avoid confusion we will always include at least a placeholder dummy variable when referring to the function e(x) and its iterates.
Finding the “logarithm” for es(1) is simpler than finding es(1). We mean logarithm in a general sense, as counting the number of times something has been done. The ordinary logarithm of Calculus counts the number of factors of e in a product, for examplelog(e e e e) = 4
and in generallog(es) = s
where s can be fractional as well as whole. The crux of the definition of log — see the discussion of mul(x) = e x above — is thatlog(mul (x) ) = log(x) + 1
We want the “logarithm” for the fourth operation to count how many times exponentiation has been done:“logarithm” of es = s
or in essence“logarithm” of exp(x) = (“logarithm” of x ) + 1
Facts About Functions
When speaking of a general function we shall always assume it is strictly increasing and smooth (infinitely differentiable). In general the “logarithm” for iterates of a function f (x) is a function A(x) defined for x > 0 such thatandA is strictly increasing and smooth
A(1) = 0
The functional equation is called Abel’s equation for f (x), after Niels Henrik Abel (1802 – 1829). A(x) counts the number of times f (x) is used in x, it is a sort of “functional logarithm” or “logarithm of iteration.” (Some authors omit A(1) = 0 from the definition, and when it is posited call the resulting A(x) a “normalized” Abel function.)
You can see from Abel’s equation that:A(f
2(x)) = A(
f
(
f
(x)
)
) = A(
f
(x)
) + 1 = A(x) + 2
f
s (x) = A
-1(
A(x) + s
)
f0 (x) = x
fs (fr (x)) = fs + r (x)
Note that
That works in reverse. If fs(x) is a continuum of iterates for f (x), that is, f0(x) = x and fs (fr (x)) = fs + r (x) , then fs can be obtained from the inverse of the functionB(s) = fs(1)
as above. First replace s with s + r :B(s + r) = fs + r (1) = fs(fr(1))
Given x let r = B -1(x). ThenB(B -1(x) + s) = fs(x)
Let A = B -1 and we have our original formula.Footnote
Given the function f, if we knew nothing more about A than Abel’s equation then A would not be unique. If A is one solution of Abel’s equation then so would be A(x) + g(A(x)) for any periodic function g with period 1 and g(0) = 0. (Abel showed that this describes all solutions of Abel’s equation.) However in the problem we consider below, in the section “To Proceed,” there is only one solution.
As might be expected from the integral formula for log x, the derivative of A(x) might be useful. Calla “derived Abel function” of f. LetThen because of the condition A(1) = 0 we have
which generalizes the famous formula for the natural logarithm (third operation). If we can determine Φ(x) we solve the iteration problem for f (x).
Take the derivative of each side of Abel’s equation, then after some manipulation we getThis is called Schröder’s equation for f (x) , after Ernst Schröder (1841 – 1902).Footnote
Although we will not need the fact, if f ’(0) = 1 thenfs(x) = Φ -1( f ’(s x) Φ(x) )
is a system of continuous iterates of f (x).
If a function f (x) is smooth, though its Taylor series might not converge at least it will be asymptotic to the function at 0 :f
(x)
=
f
(0) + f
’(0) x + 1/2 f
’’(0)
x
2 + 1/6 f
’’’(x)
x
3 + ...
as x → 0
If the function is not only smooth but real analytic the series converges and we needn’t specify “as x goes to zero.”
Asymptotic Power Series
Suppose we are given, out of the blue, an infinite seriesa0 + a1(x – x0) + a2(x – x0)2 + a3(x – x0)3 + ...
Regard this as a “formal” series, effectively just a sequence of coefficients provenance unknown. (All the subscripts in this section are indices, not the fourth operation.)
Given a particular x we could try to sum the series. The series might converge, that is, if we compute the partial sumsSn(x) = a0 + a1(x – x0) + a2(x – x0)2 + ... an(x – x0)n
thenlim Sn(x) = [some number] as n → ∞
for the particular x. In such cases we can think of the series as a function defined where it converges. The series alone could be used to define the function it converges to.
The series always converges at x = x0, but except for that value it might not converge. If it doesn’t converge anywhere besides at x0 it might appear to be useless, by itself.
Scrap the above series and suppose we are given a function F(x) instead of a series. We might not know how to compute F(x) but suppose we have an abstract definition, know what its properties are. And suppose we know it is smooth at x0, any number of its derivatives exist there. Then we can form the Taylor expansion of F at x0F(x0) + F’(x0) (x – x0) + 1/2 F’’(x0) (x – x0)2 + ... 1 / i ! F(i)(x0)(x – x0)i + ...
As before we regard this as a formal series that is not necessarily summable, in effect just a sequence of coefficients. For a finite number of terms we can compute the partial sumSn(x) = F(x0) + F’(x0) (x – x0) + 1/2 F’’(x0) (x – x0)2 + ... 1 / i ! F(n)(x0)(x – x0)n
The sequence might diverge, that is, if we fix x ≠ x0 and let n → ∞ the limit of Sn(x) might not exist. But even so the series tells something about F near x0. Instead of fixing x and letting n grow large, if we fix n and let x get close to x0, then Sn(x) will approximate F(x). As x approaches x0, not only will their difference approach zero, what is stronger their ratio will approach one.
But what good is that? We already know the series gives the correct value when x = x0, what use is an approximation of F(x) for x near x0 if what we want to know is F(x) for x well away from x0? Perhaps no use at all, unless – and this is the point – the function possesses a property that allows us to express its value at any x in terms of its value at points near x0.
If the property allows the latter to approach x0 arbitrarily closely then the asymptotic series, despite the fact that it doesn’t converge, can be used to compute F(x) for any x to any desired accuracy. We will see an example of this in the next section.
To repeat, with a convergent series, given any x (in the domain of convergence) the series converges as n → ∞. With an asymptotic series, given any n the truncated series converges as x → x0. A convergent series defines a function, an asymptotic series by itself does not – however it can be used to compute a function whose value near x0 determines its value far from x0.
Again, convergence is concerned with Sn(x) for fixed x as n → ∞ whereas being asymptotic is concerned with Sn(x) for fixed n as x → x0 when the series is the Taylor expansion of a function that has other properties besides Taylor coefficients. Convergence depends on only the coefficients, asymptoticity depends on the function as well as the coefficients.
We will use ~ to indicate asymptotic equality.Footnote
General definition applicable to any series, not just a Taylor expansion: A series with partial sums Sn(x) is asymptotic to F(x) at x0 if for each n( F(x) – Sn(x) ) / (x – x0)n → 0 as x → x0
In other words, as x approaches x0, the error in using any of the partial sums for F(x) approaches zero compared with the last term of the partial sum. Again in other words, any partial sum approaches F(x) faster than its last term approaches zero. This is automatically true if the series is the Taylor series of a smooth function.
To Proceed
As before, lete(x) = ex – 1
We posit a continuum of functions, es (x), such that:1. The es (x) as functions of x are iterates of the function e(x), that is,e1 (x) = e (x), and
e r (e s (x) ) = e r + s (x)
for all r and s.2. es (x) is smooth (infinitely differentiable) in s and in x.Given the above, we will try to find, if possible, what the continuum of functions must be.
Obviously e(x) evaluated at zero is zero. Later we will need to know that any iterate of e(x) evaluated at zero must be zero as well. This is obviously true for integral iterates:becausee
n(0) = e
n – 1(e(0)) = e
n – 1(0)
e½ (e½ (0)) = 0
Then apply e½(x) to each side of the equation to obtaine (e½ (0)) = e½ (0)
Thus e½ (0) is a fixed point of e(x). Since e(x) has but one fixed point, zero, we havee½ (0)) = 0
Now break e(0) = 0 this way:e⅔ (e⅓ (0)) = 0
Apply e⅓(x) to each side:e (e⅓ (0)) = e⅓ (0)
Thus e⅓ (0) is a fixed point of e(x), soe⅓ (0) = 0
The argument is clear, from e1 – 1/n (e1/n (0)) = 0 we can deduce:e1/n (0) = 0
for any natural number n.Then for any rational number m/n, to find em/n (0) simply apply e1/n (x) m times starting with 0. The expression collapses to 0. For example, when m / n = 2 / 3e⅔ (0) = e⅓ (e⅓ (0)) = e⅓ (0) = 0
That concludes our proof of Lemma #0.
Let A(x) be an Abel function for e(x),and a(x) the corresponding derived Abel function for e(x),LetΦ(x) = 1 / a(x) [*]
Schröder’s equation for e(x) isand using the fact that e’(x) = ex
We will try to find the Taylor series for Φ(x) at 0. We can expect only that it converges asymptotically. Then, as we shall see later, knowing Φ(x) when x is near 0 will enable us to compute it for any x . Let ci be such thatΦ(x) ~ c0 + c1 x + c2 x2 + c3 x3 + ... as x → 0+
(All subscripts on coefficients are indices.) It is fairly easy to show that both c0 and c1 must be 0. To determine c0 , take the derivative of each side of Schröder’s equation to eventually obtainΦ’(e(x)) = Φ’(x) + Φ(x)
Then by considering the particular case x = 0 we can conclude thatΦ(0) = 0
To determine c1, return to the last equation in x, above and take the derivative of each side again, again evaluate at x = 0 and we can conclude that Φ’(0) = 0
Continuing in the same vein yields nothing about Φ’’(0) but at least now we know that the series beginsΦ(x) ~ c2 x2 + c3 x3 + c4 x4 + ... as x → 0+
where we have yet to determine the coefficients c2, c3, c4, ...
To determine them we will plug the known power series for e(x) and the unknown one for Φ(x) into Schröder’s equation, then equate coefficients of the same power of x and solve for c2, c3, etc. one after the other. The trouble is that when we do it there is one degree of freedom. That is, we need to know at least one of the ci in order to solve for the others. If we knew c2 we could solve for c3, then for c4, etc. We will explain in detail when we have figured out what c2 must be and actually perform the procedure.
Finding c2 in the Taylor series for Φ(x) will take a bit of work. We will try to find the first two nonzero terms of the Taylor series for es(x) thinking of s as the variable and x as a fixed parameter. The two coefficients will be functions x. Looking ahead, one of the two will involve Φ(x) which will allow us to determine the second derivative of Φ(x) at 0 and hence c2 in the series for Φ(x) .
Later we will need the second derivative of es(x) with respect to x evaluated at x = 0, so on to that calculation, the first derivative first.
In what follows an apostrophe indicates differentiation with respect to x. To determine the first derivative we use a trick: before taking the derivative break es(x) into e(es–1(x) ) then use the chain rule to find a recursive relation for the derivative.e
s(x) = e(e
s–1(x))
e
s’ (x) = e
’(e
s–1(x))
·
e
s–1’ (x) [**]
es’ (0) = es–1’ (0)
Repeating that formula within itself on the right we get down towhere 0 ≤ t < s is the fractional part of s, that is, the number left over after subtracting from s the largest whole number less than s.
In the particular case when s is a whole number n, that is when t = 0 and thus et (x) = xen’ (0) = 1
That suggests the following:for all s. We need prove it only on a unit interval, say s between 0 and 1. We shall prove it for rational numbers, then by continuity it must hold for all real numbers. First consider the identityTake the derivative of each side,e
’(x) = e
½’(e
½(x))
·
e
½’(x)
e
’(0) = e
½’(e
½(0))
·
e
½’(0)
1 = e
½’(0)
·
e
½’(0)
1 = e
⅓’ (0)
·
e
⅓’ (0)
·
e
⅓’ (0)
Given any function f (x) and as usual letting fn(x) be its nth iterate, thenf n’ (x) = f ’(f n–1(x)) · f ’(f n–2(x)) · f ’(f n–3(x)) · ... · f ’(x)
or using ⚬ to indicate functional compositionf n’ = the products of f ’ ⚬ f n–k
as k goes from 1 to n.
Now that we know the result when s is near the left end of the 0 to 1 interval we can work from the right end back to the left.For n ≥ 1, consideringe(x) = e
1 – 1/n (e
1/n (x))
e
’(x) = e
1 – 1/n ’(e
1/n(x))
·
e
1/n’(x))
e(x) = e
1 – 2/n (e
1/n (e
1/n (x)))
e(x) = e
1 – 3/n (e
1/n (e
1/n (e
1/n (x))))
In general, for any function f (x) having a fixed point at x = a,f s ’(a) = (f ’(a)) s
Now for the second derivative of es(x) evaluated at x = 0.
For typographical reasons in what follows let D as well as apostrophe denote d/dx, differentiation by x, and let D2 as well as double apostrophe denote differentiation twice. Start by taking the derivative of each side of the equation marked [**] near the beginning of the previous subsection above:D
2[ e
s(x) ] = D[ e
’(e
s–1 (x)
)
·
e
s–1 ’(x) ]
e
s ’’(x) = e
’’(e
s–1 (x)
)
·
e
s–1 ’(x)
·
e
s–1 ’(x) + e
’(e
s–1 (x)
)
·
e
s–1 ’’(x)
e
s ’’(0) = 1 + e
s–1 ’’(0)
e
s ’’(0) = 1 + 1 + e
s–2 ’’(0)
es ’’(0) = n + e t ’’(0)
where n is the largest whole number ≤ s and t = s – n .
In the particular case when s is an integer, that is, s = n, t = 0, and thus et (x) = xen ’’(0) = n
That suggests the following:for all s. As before, we need prove it only for rational numbers between 0 and 1. First consider the identityTo save typing let g(x) = e½ (x) and keep in mind for later that g(0) = 0 and (Lemma #1) g’(0) = 1. The above identity isTake the derivative of each side,In what follows we use the product rule for derivatives. If u and v are functions of x,D(u
·
v) = D(u)
·
v
+
u
·
D(v)
e
’’(x) = g
’’(g(x))
·
g
’(x)
·
g
’(x) + g
’(g(x))
·
g
’’(x)
e
’’(0) = g
’’(0) + g
’’(0)
1 = 2
g
’’(0)
We next consider the case s = ⅓ in such a way that the generalization to s = 1 / n will be clear. Recall that the formula for the derivative of the product of three variables is:D(u
·
v
·
w) = Du
·
v
·
w + u
·
Dv
·
w + u
·
v
·
Dw
Let g(x) = e⅓ (x). Thenande
’(x) = g
’(g
(g(x)))
·
g
’(g(x))
·
g
’(x)
Label the three factors ①, ②, and ③. Then
e’’(x) = ①’ · ② · ③ + ① · ②’ · ③ + ① · ② · ③’
Now evaluate this at x = 0. The left side is 1. On the right, each of the three terms consists of one g’’(iterates of g evaluated at 0) times lower derivatives of g evaluated at 0. Because g(0) = 0, what is inside each g’’( ) collapses to zero, and because g’(0) = 1 what each g’’(0) is multiplied by collapses to 1. The net result is1 = g
’’(0)
+
g
’’(0)
+
g
’’(0)
In general, for s = 1/n , (1) the first derivative is a product of n variables, (2) there are exactly n terms in the derivative of that product, (3) because of the values of g(0) and g’(0), each of the n terms equals g’’(0). Thus
As in our proof of Lemma #1, now that we know the result when s is near the left end of the 0 to 1 interval we can work from the right end back to the left. First we will warm up by considering the particular case s = 1 – 1/n and s – 2/n, then prove it in general for s = 1 – k/n, k = 0 to n. The warm up is unnecessary but helps to understand the general proof.For n ≥ 1, letandThenTaking the first derivative,e
’(x) = h
’ (g
(x))
·
g
’(x)
e
’’(x) = h
’’ (g
(x))
·
g
’(x)
·
g
’(x) + h
’ (g
(x))
·
g
’’(x)
e
’’(0) = h
’’ (g
(0))
·
g
’(0)
·
g
’(0) + h
’ (g
(0))
·
g
’’(0)
e(x) = h
(g
(g
(x)))
e
’(x) = h
’ (g
(x))
·
g
’(x)
·
g
’(x)
① ② ③
e
’’(x) = ①
’ ·
②
·
③ + ①
·
②
’ ·
③ + ①
·
②
·
③
’
e
’’(x) = h
’’(0)
+
g
’’(0)
+
g
’’(0)
1 = h
’’(0) + 1/n + 1/n
h
’’(0) = 1 – 2/n
e
1 – 2/n ’’(x) = 1 – 2/n
In general, let g(x) = e 1/n (x) and let g m (x) be its mth iterate:g m (x) = g(g(g(...(x)))) m times
so thatAnd letThene(x) = h
(g
m (x))
e
’(x) = h
’ (g
m (x))
·
g
m’(x)
g
m ’(x) = g
’(g
m–1(x))
·
g
’(g
m–2(x))
·
g
’(g
m–3(x))
·
...
·
g
’(x)
e
’(x) = h
’ (g
m (x))
·
P(x)
e
’’(x) = h
’’(g
m (x))
·
P(x)
·
P(x) + h
’ (g
m (x))
·
P
’(x)
e
1 – m/n ’’(0) = 1 – m/n
Footnote
At this point we could find the power series for es(x) in terms of x.
Consider es(x) as a function of x with s as a parameter. Consider its Taylor expansion at x = 0es(x) ~ c0 + c1 x + c2 x2 + c3 x3 + ... as x → 0+
(The coefficients here differ from those in earlier paragraphs; we use the letter “c” for the coeficents of any series.) The coefficient ci is a function of s , namely the ith derivative of es(x) with respect to x divided by i ! evaluated at x = 0 .
From our lemmas es(0) = 0, es ’(0) = 1, and es ’’(0) = s. Thus c0 = 0, c1 = 1, and c2 = ½ s. So the power series for es(x) begins:es(x) ~ x + ½ s x2 + c3 x3 + ... as x → 0+
We do not need any more lemmas about es(n)(0). The rest of the coefficients can be determined by breaking es+1(x) two wayse(es(x)) = es(e(x))
and plugging in the known power series for e(x) and what we know of the power series for es(x) and equating coefficients of like powers of x. However we shall focus on finding the simpler Φ(x).
Now consider es(x) as a function of s with x as a parameter. Let its Taylor expansion at s = 0 bees(x) ~ c0 + c1 s + c2 s2 + c3 s3 + ... as s → 0
The coefficients ci are functions of x , namely the ith derivative of es(x) with respect to s evaluated at s = 0 divided by i ! .
Since e0(x) = x right away we know c0 = x .
Now c1 is the first derivative of es(x) with respect to s evaluated at s = 0. To find that consider an Abel function for e(x)A(e(x)) = A(x) + 1
A(e
s(x)) = A(x) + s
e
s(x) = A
-1(
A(x) + s
)
e
s’ (x) = 1 / A
’(A
-1(A(x) + s)
)
= 1 / A
’(e
s(x))
= 1 / a(e
s(x)
)
e0’ (x) = 1 / a(x) = Φ(x)
So the power series in s beginses(x) ~ x + Φ(x) s + c2 s2 + c3 s3 + ... as s → 0
where each coefficient depends on x.
One of the requirements on the left side expression is that its derivative with respect to x exits, thus we can differentiate the asymptotic series term by term. As s → 0e
s’(x) ~ 1 + s Φ
’(x) + [higher powers of
s
times functions of
x]
e
s’’(x) ~ s Φ
’’(x) + [higher powers of
s
times functions of
x]
lim (
s Φ
’’(x) + [higher powers of
s]
) / e
s’’(x) = 1
s → 0lim (
s Φ
’’(0) + [higher powers of
s]
/ s = 1
s → 0
We are trying to find Φ(x) . Earlier we had shown that its Taylor expansion beginsΦ(x) ~ c2 x2 + c3 x3 + c4 x4 + ... as x → 0+
and now we know that the second-order coefficient c2 = ½ Φ(x) ~ ½ x2 + c3 x3 + c4 x4 + ... as x → 0+
This will enable us to compute the other coefficients.
Start with Schröder’s equationΦ(e(x)) = ex Φ(x)
The power series for ex isex = 1 + x + 1/2 x2 + 1/6 x3 + ...
and for e(x)e (x) = x + 1/2 x2 + 1/6 x3 + ...
First consider the third order coefficient of Φ(x)Φ(x) ~ 1/2
x
2 +
c
x
3 + [higher powers of x]
1/2 x2 + (c + 1/2) x3 + (3/2 c + 7/24) x4 + [higher powers of x]
and the right1/2 x2 + (c + 1/2) x3 + (c + 1/4) x4 + [higher powers of x]
Thus, focusing on the fourth order terms,3/2 c + 7/24 = c + 1/4
we havec = – 1/12
Then think of Φ(x) asΦ(x) ~ 1/2
x
2 –
1/12
x
3 +
c
x
4 + [higher powers of x]
2 c + 1/48 = c + 1/24
and solving for cc = 1/48
Continuing in this manner we can determine the coefficients one after the other.
Φ(x) ~ 1 / 2 x2 – 1 / 12 x3 + 1 / 48 x4 – 1 / 180 x5 + 11 / 8640 x6 ...
as x → 0+ |
The coefficients continue (as the exponent of x goes from 7 to 10):–
1
/
6720, 11
/
241920, 29
/
14551520, 493
/
43545600, ...
Now that we have an asymptotic power series for Φ(x) as x → 0+ we can use it, together with known properties of the function Φ(x), to calculate Φ(x) for any x .
First note that the inverse e–1(x), where e(x) = exp(x) – 1, ise–1(x) = log(1 + x)
Repeated application of this function takes a positive number arbitrarily close to zero:Thus suppose we are given x = x0 > 0. Here a subscript on x is a sequential index, not the fourth operation. Then the sequencex0
x1 = e–1(x0)
x2 = e–2(x0)
...
xn = e– n(x0)
can be continued far enough (n can be made large enough) so that xn is as small as desired.
Now apply Schröder’s equationto x1Φ(x0) = Φ(e(x1)) = ex1 Φ(x1)
then to x2Φ(x1) = Φ(e(x2)) = ex2 Φ(x2)
ThusΦ(x0) = ex1 ex2 Φ(x2)
And so on through xnΦ(x0) = ex1 ex2 ... exn Φ(xn)
Since xi+1 = e–1(xi) = log(1 + xi) we have
| Φ(x0) = (1 + x0) (1 + x1) ... (1 + xn–1) Φ(xn) |
We can use this equation to, in a manner of speaking, drop any x = x0 > 0 down to near zero (though it does so with increasing slowness). Call it the “drop-down” formula. Thus with our asymptotic expansion of Φ(x) at 0 we can compute Φ(x) for any x.
The function Φ(x) is unique because we have calculated what it must be.
Having Φ(x) we can compute (see the middle of the section “Facts About Functions” above) the “functional logarithm” for e(x) fromA (x) = ∫1x 1 / Φ(t) dt
Then the functional iterates of e(x) are
Note thates(1) = A – 1(s)
So if we know A – 1(s) for 0 ≤ s < 1 we know it for all s.
Since the uniqueness of Φ(x) is so important we shall prove it again without resorting to an asymptotic expansion, simplifying an argument of Szekeres.
Let Φ(x) be the reciprocal of a derived Abel function for e(x). We shall prove that if Φ(0) = Φ’(0) = 0, and Φ’’(0) exists and ≠ 0 then Φ(x) is unique.
(Earlier we proved the conditions on Φ(0) and Φ’(0), and an even stronger condition on Φ’’(0), that it equals 1, but we will need only the weaker condtion.)
In our proof we will eventually use the fact, implied by the conditions,lim Φ(x) / x2 exists and ≠ 0 [***]
x → 0
Call this constant C .
Suppose there were another derived Abel function for e(x) whose reciprocal, call it Φ*(x), satisfied our conditions. We want to show it must be that Φ* = Φ.
Choose one x = x0 and consider the sequenceyn = e– n(x0)
It goes to 0 (see earlier text). Then use Schröder’s equation for each of the two Φ to express yn in terms of x0. By substituting e– n(x) for x, we see that for the two ΦΦ(e– 1(x)) = e–x Φ(x)
ThusΦ(e– n(x)) = e–n Φ(x)
So for the two ΦΦ(yn) = e–n Φ(x0)
Φ*(yn) = e–n Φ*(x0)
Thus their ratio doesn’t depend on n. Call the ratio r.r = Φ*(y
n) / Φ(y
n) = Φ*(x
0) / Φ(x
0)
From [***] above we knowlim
Φ(y
n)
/
y
n2 = C
n → ∞lim
Φ*(y
n)
/
y
n2 = C / r
n → ∞Φ*(x) = r Φ(x)
for every x.
Since by assumption both Φ and Φ* furnish the same Abel function for e(x), both the integrals∫1x 1 / Φ(t) dt
and∫1x 1 / Φ*(t) dt
equal A(x) for all x. Since Φ* = r Φ we havefor all x. Now the function A is not identically zero, for example A(e(1)) = 1. Thus when x = e(1) the above isThus r = 1 and Φ* = Φ.
To recapitulate, we have proved the following TheoremLet
e(x) = e
x – 1. There exists a continuum of functions,
es (x)
defined for all
s
and nonnegative
x,
having the following properties:
1.
The
e
s (x)
as functions of
x
are iterates of the function
e(x),
that is,
e1 (x) = e (x), and
e r ⚬ e s (x) = e r + s (x)
for all
r
and
s.
2.
e
s (x)
is smooth (differentiable to all orders) in
s
and in
x.
3.
The continuum of functions is uniquely determined from the above assumptions. Given
s
and
x, e
s (x)
can be computed using the last two boxed formulas above — the asymptotic formula for
Φ(x)
and the drop-down formula — and the formulas for
A(x)
and
e
s(x)
just below those.
The Original Problem
We began by asking what is the number e to itself a fractional number of times. We reformulated the problem as finding the fractional iterates of the function exp(x). Then instead of solving that problem we found the fractional iterates of a somewhat different function e(x) = exp(x) – 1.
Knowing how to compute the fractional iterates of e(x) will enable us to compute the fractional iterates of exp(x). The idea is to use integral iterations of exp(x), which we know already, then introduce a fractional iteration of e(x) which will differ a little from the desired fractional iteration of exp, then take an iterated log so the error is reduced and the original integral iteration of exp is undone. The error goes to zero as the number of integral iterations increases. We now give the details.
First some notation. We wantexp n (exp m (x) ) = exp n+m (x)
to hold for all integers so let exp-1 be the inverse of exp:exp-1(x) = log(x)
exp-2(x) = log(log(x))
etc.
We need define the fractional iterates exps(x) only for 0 ≤ s < 1 because exps(x) for larger values of s can then be found by repeated application ofexp
s+1 (x) = exp
(exp
s (x)
)
exp
s–1 (x) = exp
–1 (exp
s (x)
) = log
(exp
s (x)
)
We assume (that is, we require of our definition) thatexp r (exp s (x) ) = exp r+s (x)
for r and s fractional just as when they are integral.
Recall that e(x) = exp(x) – 1 and es(x) is its factional iteration.
Let n be a whole number and considerexps(x) = exp –n (exp n+s (x) ) = exp–n(exps(expn(x) ) )
Since exp –n is log iterated n times,exps(x) = log n (exp s (exp n (x) ) )
The idea is to replace the exps() on the right with es() and let the iterated exp / log wash out the difference as n grows large. (The log will still be operating on a number greater than zero. For each x, es(x) is an increasing function of s. Since e0(x) = x, when s ≥ 0 we have es(x) ≥ x.)Footnote
es(x) is an increasing function of s becausees(x) = A-1( A(x) + s )
and since A() is strictly increasing so is its inverse.
Defineexps(x) = lim log n (e s (exp n (x) ) )
n → ∞
or using ⚬ to indicate functional composition:
exps(x) = lim log n ⚬ e s ⚬ exp n (x)
n → ∞ |
In practice the limit converges very rapidly. So rapidly in fact that n = 2 or 3 is enough for eight significant figures of exps(1).
Exps(x) thus defined is a continuum of iterates for exp(x). Even for finite n we have (where I is the identity function, I(x) = x)log n ⚬ e 0 ⚬ exp n = log n ⚬ I ⚬ exp n = log n ⚬ exp n = I = exp 0
Now considerexp r ⚬ exp s = lim log m ⚬ e r ⚬ exp m ⚬ lim (log n ⚬ es ⚬ exp n)
m → ∞ n → ∞
On the right, because the functions are continuous, the composition of the three leftmost ones is continuous and we can move the limit on n outsidelim lim log m ⚬ e r ⚬ exp m ⚬ logn ⚬ e s ⚬ exp n
m, n → ∞
Since the limit on m exists for each fixed n and vice versa, we can choose m = n, so the above equalslog n ⚬ e r ⚬ es ⚬ exp n = log n ⚬ e r+s ⚬ exp n
in the limit as n → ∞. Thusexp r ⚬ exp s = exp r+s
that isexp r (exp s (x)) = exp r+s (x)
as desired.
It is interesting to compare exps(x) and es(x) as x increases. The following table shows their difference to three decimal places for s between 0 and 1.
\ x
\
s \ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | … |
| 0.00 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | … |
| 0.25 | 0.173 | 0.114 | 0.064 | 0.031 | 0.013 | 0.006 | 0.002 | 0.001 | 0.000+ | 0.000+ | … |
| 0.50 | 0.374 | 0.261 | 0.150 | 0.075 | 0.036 | 0.017 | 0.008 | 0.003 | 0.002 | 0.001 | … |
| 0.75 | 0.633 | 0.498 | 0.340 | 0.217 | 0.134 | 0.080 | 0.047 | 0.027 | 0.015 | 0.008 | … |
| 1.00 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | … |
Naturally if s = 1 the difference is always exactly one but if s < 1 the difference goes to zero, and rapidly, with increasing x .
Now to answer the question we started with, what is e to itself one half times, we compute exp ½ (1) using the above limit formula. With seven decimal places the sequence stabilizes after n = 2.
| n | formula |
| 0 | 1.2710274 |
| 1 | 1.6100969 |
| 2 | 1.6451508 |
| 3 | 1.6451508 |
As a check that this great web of arithmetic hangs together we compute exp ½ (exp ½ (1) ). By n = 2 it has stabilized to seven decimal places at 2.7182818, which is, as it should be, exp(1) = e.
The following table shows how fast the fourth operation grows as the second operand increases. The numbers in the right column are to three decimal places. The zeros at the end of the higher numbers are just placeholders due to the limited precision of the computer.
s es
0.000 1.000
0.125 1.141
0.250 1.293
0.375 1.460
0.500 1.645
0.625 1.855
0.750 2.097
0.875 2.380
1.000 2.718
1.125 3.130
1.250 3.644
1.375 4.305
1.500 5.182
1.625 6.392
1.750 8.141
1.875 10.807
2.000 15.154
2.125 22.879
2.250 38.261
2.375 74.059
2.500 178.001
2.625 597.197
2.750 3431.358
2.875 49362.812
3.000 3814279.105
3.125 8632298240.322
3.250 41348087974198336.000
3.375 145673789637930926000000000000000.000
3.500 201844519565335862000000000000000000000000000000000000000000000000000000000000.000
Here is the graph of y = ex with the y axis shrunk in order to show more of the graph.
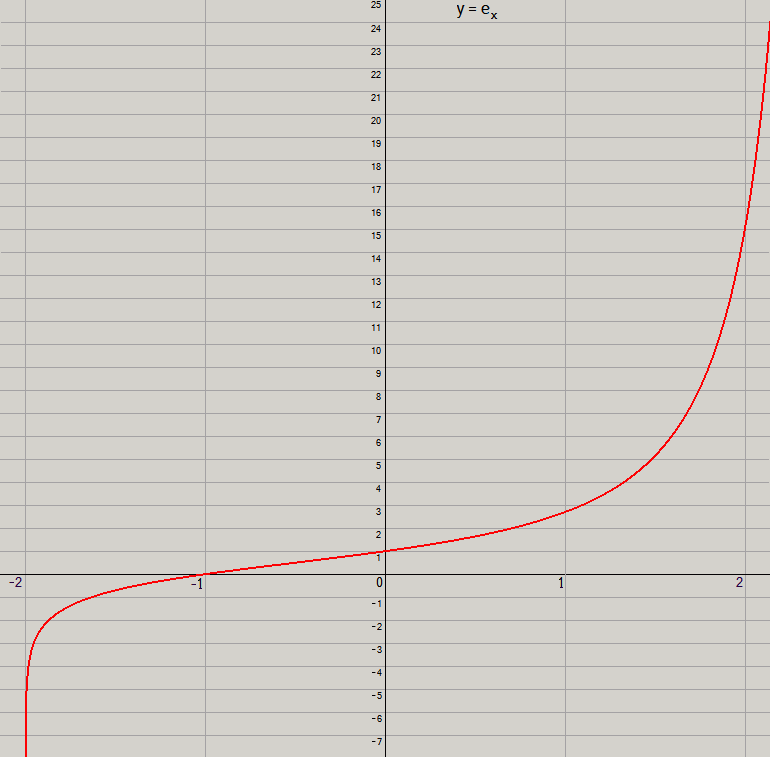
Features to note:e
x is undefined for
x ≤ –2. (It would involve the logarithm of a non-positive number.)
As
x → –2
+, e
x → –∞.
When
x = –1, e
x = 0.
When
x = 0, e
x = 1.
When
x = 1, e
x = e = 2.71828
... .
There is a point of inflection between
–1
and
0. A graph is fairly straight near a point of inflexion; this graph is fairly straight throughout the entire interval from
x = –1 to 0. Throughout that interval
e
x differs from
x + 1
by less than
.01
.
Computer Program I
The following computer program can be modified for Visual Basic, FORTRAN and any other BASIC-like compiler.
This glossary translates the computer program functions into the mathematical functions of the above analysis when e(x) = exp(x) – 1.
| Program | Analysis |
| DeLog(x) | A’(x) = a(x) = 1 / Φ(x) |
| AsympDeLog(x) | 1 / asymptotic power series for Φ(x) |
| eLog(x) | A(x) |
| eExpInteger(n, x) | en(x) |
| eExp(x) | A – 1(x) |
| ExpInteger(n, x) | expn(x) |
| ExpReal(s, x) | exps(x) |
' The Fourth Operation I
'------------------------------------------------------------
Macro Precision = Double '15 or 16 significant digits
Macro expRealTol = .00000001
Macro eExpTolNewton = .00000001
Macro eLogDxMax = .01
Macro CheckExit = If exitflag Then Exit Function
Global e, em1, DeLog1 As Precision 'constants
Global exitflag, overflowflag As Long 'flags
'------------------------------------------------------------
%ht = 8 'cut off in power series, 8 max -- see Dim coef and Assign coef
Function AsympDeLog(x As Precision) As Precision
Local i As Long
Local sum As Precision
Dim coef(8) As Static Precision 'make static so need assign only once
CheckExit
' 0 1 2 3 4 5 6 7 8
If coef(2) = 0 Then 'first call?
Array Assign coef() = 0, 0, 1/2, -1/12, 1/48, -1/180, 11/8640, -1/6720, -11/241920
End If
If x < 0 Then
Print "AsympDeLog: out of bounds" :exitflag = 1
Exit Function
ElseIf x = 0 Then
Function = 0
Exit Function
End If
' sum starts as 0
For i = 2 To %ht 'terms to x^5 give at least five decimal places if x < .05
sum = sum + coef(i) * x^i
Next
Function = 1 / sum
End Function
'------------------------------------------------------------
%maxLogRep = 20
Function DeLog(x As Precision) As Precision
Dim xx(%maxLogRep) As Precision
Local d As Precision
Local i, n As Long
CheckExit
If x < 0 Then
Print "DeLog: out of bounds" :exitflag = 1
Exit Function
ElseIf x = 0 Then
Function = 0
Exit Function
End If
' n starts as 0
xx(0) = x
Do
Incr n :If n > %maxLogRep Then Print "DeLog: failed" :exitflag = 1 :Exit Function
xx(n) = Log(1 + xx(n - 1))
Loop Until xx(n) < .1 'anything smaller doesn't affect output before 6 decimal places
'the smaller this, the larger %maxLogRep must be
d = 1
For i = 0 To n - 1
d = d * (1 + xx(i))
Next
Function = AsympDeLog(xx(n)) / d
End Function
'------------------------------------------------------------
Function eLog(ByVal x As Precision) As Precision 'integrate DeLog(t) from 1 to x
Local cnt As Long 'use Romburg's Method of integration
Local i, k, nmax As Long
Local p As Long
Local sum, h, dx As Precision
CheckExit
If x = 1 Then
Function = 0
Exit Function
End If
' cnt starts as 0
Do Until x < em1 'get x < e - 1, eLog(x) < 1
x = Log(1 + x)
Incr cnt
Loop
dx = eLogDxMax 'want nmax so abs(x - 1) / 2^nmax <= dx
Do Until dx < Abs(x - 1) 'is dx small enough?
dx = dx / 2
Loop
nmax = 1 + Log2(Abs(x - 1)/dx) 'add one to ensure at least one
Dim R(nmax,nmax) As Precision 'nmax does not exceed 7
'now finished with dx, all we needed was nmax
h = (x - 1) / 2
R(0,0) = h * (DeLog1 + DeLog(x)) 'DeLog1 = DeLog(1)
For i = 1 To nmax
h = (x - 1) / 2^i
sum = 0
For k = 1 To 2^(i-1)
sum = sum + DeLog(1 + (2*k-1)*h)
Next
R(i,0) = R(i-1,0)/2 + h*sum
p = 1
For k = 1 To i
p = p * 4
R(i,k) = R(i,k-1) + (R(i,k-1) - R(i-1,k-1))/(p-1) 'p = 4^k
Next
Next
Function = R(nmax,nmax) + cnt
End Function
'------------------------------------------------------------
Function eExpInteger(n As Long, ByVal x As Double) As Precision 'e sub n (1)
Local i As Long
CheckExit
overflowflag = 0
For i = 1 To n
x = Exp(x) - 1
If x = 1/0 Then overflowflag = 1 :Exit Function
Next
Function = x
End Function
'------------------------------------------------------------
%maxNewtonRep = 20
Function eExp(ByVal y As Precision) As Precision 'inverse of eLog, y >= 0
Local x, xlast As Precision
Local n, cnt As Long
CheckExit
cnt = 0 'get fractional part of y
Do Until y < 1
Decr y
Incr cnt
Loop
Do Until y >= 0
Incr y
Decr cnt
Loop
' here 0 <= y < 1, cnt = integral part of original y
' Newton-Raphson Method, it uses the derivative of eLog.
' n starts as 0
x = 1
Do
xlast = x
x = xlast + (y - eLog(xlast)) / DeLog(xlast)
Incr n
If n > %maxNewtonRep Then Print "eLog: hung" :exitflag = 1 :Exit Function
Loop Until Abs(x - xlast) < eExpTolNewton
Function = eExpInteger(cnt, (x + xlast) / 2) 'this will be 0 if overflow
End Function
'------------------------------------------------------------
' n must not exceed 3 or 4 (depends on x) to avoid overflow. And:
' If n = -1, x must > 0, if n = -2, x must > 1, if = -3, x must > e, ...
' in general if n < 0, x must > ExpInteger(-2 - n ,1)
Function ExpInteger(n As Long, ByVal x As Precision) As Precision
Local i As Long
CheckExit
If n >= 0 Then
For i = 1 To n
x = Exp(x)
Next
Else
For i = 1 To -n
If x <= 0 Then
Exit Function
Else
x = Log(x)
End If
Next
End If
Function = x
End Function
'------------------------------------------------------------
' This is the principal function.
Function ExpReal(ByVal s As Precision, ByVal x As Precision) As Precision
Local p, y, z, zlast As Precision
Local cnt, n As Long
' cnt starts as 0
Do Until s < 1 'get fractional part of s
Decr s
Incr cnt
Loop
Do Until s >= 0
Incr s
Decr cnt
Loop
' here 0 <= s < 1, cnt = integral part of original s
If s = 0 Then
Function = ExpInteger(cnt, x)
Exit Function
End If
If x < 0 Then 'get 0 <= x < e
x = Exp(x)
Decr cnt
ElseIf x >= e Then
Do Until x < e
x = Log(x)
Incr cnt
Loop
End If
' n starts as 0, z starts as 0
Do
zlast = z
p = eLog(ExpInteger(n, x))
y = eExp(p + s)
If overflowflag Then 'this flag is set in eExpInteger, called by eExp
z = 0
Exit Do
End If
z = ExpInteger(-n, y)
Incr n
Loop Until Abs(z - zlast) < expRealTol Or z = 0 Or exitflag = 1
If z = 0 Then
Function = ExpInteger(cnt, zlast)
Else
Function = ExpInteger(cnt, z)
End If
End Function
'===========================================================================
%list = 1
%socket = 2
%graph = 3
%which = %socket 'one of the above
%xd = 180 'used in the %graph case
%yf = 23
Function Main
Local w, h, a, b As Long
Local s As Precision
Desktop Get Size To w, h 'set up console window
Console Get Size To a, b
Console Set Loc (w - a)\2, (h - b)\2
Console Set Screen 120, 100
e = Exp(1) 'global constants
em1 = e - 1
DeLog1 = DeLog(1)
Print Exp(-15)
#If %which = %list '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Print " "; " s", " e sub s"
Print " "; "----------------------"
For s = -1 To 3.5 Step .125
Print " "; Format$(s,"* .000;-0.000"), Format$(ExpReal(s, 1)," #.00000")
Next
WaitKey$
#ElseIf %which = %socket '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Local x As Precision
Print " *** to exit, click X at upper right corner ***" :Print
Print " This demonstration doesn't check that s and x are within"
Print " bounds. It will give a nonsensical result if in the course"
Print " of the calculation the logarithm of a negative number would
Print " have to be performed or a number is computed that is larger
Print " than double precision can handle." :Print
Do
Input " Enter s operand: "; s
Input " Enter x socket: "; x
Print " exp sub"; s; "(";Format$(x,"#.0#####");") = "; Format$(ExpReal(s, x)," #.000000")
Print
Loop
#Else '%which = %graph '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Local i, c As Long
Local x, y As Precision
Local winC As Dword
Print " *** to exit, click on this window and press Esc ***" :Print
Graphic Window "", 100, 0, 768, 768 To winC 'set up graphic window
Graphic Attach winC, 0
Graphic Scale (-384,384+200) - (384,-384+200)
Sleep 1
For i = -9 To 29 'horizontal lines
If i = 0 Then c = %Black Else c = &hA0A0A0
Graphic Line (-384,i*%yf)-(384,i*%yf), c
Next
For i = -2 To 3 'vertical lines
If i = 0 Then c = %Black Else c = &hA0A0A0
Graphic Line (i*%xd,-384+200)-(i*%xd,384+200), c
Next
Graphic Width 2 'graph
x = -2*%xd + .000001
y = %yf*ExpReal(x/%xd, 1)
Graphic Set Pixel (x, y)
For x = -2*%xd + .000001 To 2.3*%xd
y = %yf*ExpReal(x/%xd, 1)
Graphic Line -(x,y), %Red
If InStat And InKey$ = $Esc Then Exit Function
Next
WaitKey$
#EndIf '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
End Function
'------------------------------------------------------------
Another Path to the Same Destination
In finding the power series for Φ(x), the reciprocal of the derived Abel function for ex – 1, we noted in a footnote that we could consider es(x) as a function of x with s as a parameter and showed that the power series for it begins:e
s(x) ~ x + ½ s x
2 + ... as x → 0
+
However we now resume the earlier line of inquiry. It offers a way to compute es(x) directly and a different way to determine the Abel function A(x) instead of integrating 1 / Φ(t) from 1 to x.
We need to compute more terms of the power series above. The rest of the coefficients can be determined by breaking es+1(x) two wayse(es(x)) = es(e(x))
and plugging in the known power series for e(x) and what we know of the power series for es(x), then equating coefficients of like powers of x. As with the power series for Φ(x) a symbolic algebra calculator will help. We already haveUsing the above procedure we find that the next three coefficients arec3 = – 1/12 s + 1/4 s2
c4 = 1/48 s – 5/48 s2 + 1/8 s3
c5 = – 1/180 s + 1/24 s2 – 13/144 s3 + 1/16 s4
so that es(x)
-as x → 0 | ~ | x + 1/2 s x2 + (– 1/12 s + 1/4 s2) x3 + (1/48 s – 5/48 s2 + 1/8 s3) x4 + (– 1/180 s + 1/24 s2 – 13/144 s3 + 1/16 s4) x5 + ... |
As a check, try s = 1. In that case the coefficient of each power of x is the sum of the coefficients of the powers of s within it: 1, 1/2, 1/6, 1/24, 1/120, ..., which begins the Taylor expansion of e(x) = ex – 1, as it should. (The series in that particular case converges for all x, which is not typical. I. N. Baker has shown that the function es(x) is analytic only when s is integral.)Footnote
If we rearrange the series in powers of s:| es(x) | ~ | x + (1/2 x2 – 1/12 x3 + 1/48 x4 – 1/180 x5 + ...) s + (1/4 x3 – 5/48 x4 + 1/24 x5 + ...) s2 + (1/8 x4 – 13/144 x5 + ...) s3 + (1/16 x5 + ...) s4 + ... |
Note that s in the boxed series needn’t be near zero, it can be any number. As for x, in general only when it is near zero does the series give a good approximation. It can approach zero from above or below.
To use the series for a given x much different from zero, either raise or lower it by computingek(x)
for k = 0, 1, 2, ... or k = 0, –1, –2, ..., depending on whether x is less than or greater than zero, until ek(x) is near zero according to our chosen tolerance. Let n be that final k. Given s, we can use our power series to approximateCall it y. Then
Though the power series works for s any distance from zero it gives a little better approximation if s is between zero and one. We can add a whole number m, positive or negative, to s to get into that range, then after using the power series apply e–m() to undo that operation. We can combine the two undoings, the one for x and the one for s, and just use n + m in the last formula above instead of n.
The following computer program implements this procedure. x near 0 is taken to mean |x| < .05, which makes the result accurate to about seven figures.
' e sub s (x) directly using power series
'------------------------------------------------------------
Macro Precision = Double
Macro tol = .05
Global overflowflag As Long
'------------------------------------------------------------
Function eIterate(ByVal s As Precision, ByVal x As Precision) As Precision
Local cnt, i As Long
Local ss, sss As Precision
Local y As Precision
Local t As Precision
cnt = Int(s) 'integer part of s
s = s - cnt 'fractional part of s, it is now 0 <= s < 1
Do Until x < tol 'drop x down to less than tol
x = Log(x + 1)
Incr cnt
Loop
Do Until x > -tol 'raise x up to greater than 0
x = Exp(x) - 1
Decr cnt
Loop
ss = s*s
sss = ss*s
y = x + _
(s/2) * x^2 + _
(-s/12 + ss/4) * x^3 + _
(s/48 - 5*ss/48 + sss/8) * x^4 + _
(-s/180 + ss/24 - 13*sss/144 + sss*s/16) * x^5
If cnt > 0 Then
For i = 1 To cnt
t = y
y = Exp(y) - 1
If y < t Then
overflowflag = 1
Exit Function
End If
Next
ElseIf cnt < 0 Then
For i = 1 To -cnt
y = Log(y + 1)
Next
End If
Function = y
End Function
'------------------------------------------------------------
Function PBMain
Local w, h, a, b As Long
Local s, x, y As Precision
Desktop Get Size To w, h 'set up console window
Console Get Size To a, b
Console Set Loc (w - a)\2, (h - b)\2
Console Set Screen 120, 100
Print " *** to exit, click X at upper right corner ***" :Print
Print
Do
Input " Enter s parameter: "; s
Input " Enter x variable: "; x
overflowflag = 0
y = eIterate(s, x)
If overflowflag Then
Print " overflow"
Else
Print " e sub"; s; "(";x;") = "; Format$(y," #.00000000000000")
End If
Print
Loop
WaitKey$
End Function
'-----------------------------------------------------------------
In the section “To Proceed” we computed the Abel function A(x) for e(x) = ex – 1 on the way to computing es(x). In the above we used a power series for es(x) to compute es(x) directly.
The es(x) power series can also be used to compute A(x). Recall that the Abel function for e(x) is a sort of “functional logarithm” or “logarithm of iteration” that measures the amount of iteration of e(x) in a variable. Precisely (see the section “Facts About Functions” above and apply it to f(x) = e(x) = ex – 1) these two equations are equivalent:Now suppose we have the power series beginning this section. Given x ≥ 1, we can use it to compute A(x) as follows.
We already know A(1) = 0. Let x = x0 > 1. Then computexk = e–k(x)
for k = 0, 1, 2, ... (here k is just a subscript), making k large enough so that xk is near zero according to our chosen tolerance. Let n equal that last k. Letun = e–n(1)
It will be even nearer zero.
Now consider the differenceIt isA(e–n(x)) – A(e–n(1))
or( A(x) – n ) – ( A(1) – n )
The n’s cancel. Since A(1) = 0 we haveindependent of n.
Recall that our goal is to find A(x) given x. Let s = A(x). The following are equivalent:A(x
n) – A(u
n) = s
A(x
n) = s + A(u
n)
x
n = e
s(u
n)
We need compute A(x) only for x less than e – 1, that is, x in the range [1, e – 1). From such values of A(x) we can determine A(x) for greater x by using e–1() and the formula for A():where the whole number k is just large enough so that e–k(x) <= 1. To find A(x) for x in the range (0, 1] use A(x) = A(e(x)) – 1.Footnote
The last part of this section is a simplified account of the method given in Morris & Szekeres’s addendum to the first reference cited in our “Introduction.” Our lemmas #0, #1, and #2 allowed us to prove that the second-order coefficient in the power series above is ½ s, patching a serious gap in their argument.
Morris & Szekeres go out of the way to, in a manner of speaking, bring s near zero as well as x and 1 but that is unnecessary if each coefficient, a finite series in s, is determined in full instead of truncating them. (Truncating these finite series probably contributed to the accumulation error they mention.)
Computer Program II
We can use the computer code at the end of the first part of the previous section “Another Path” – which iterates e(x) – along with the “wash out” procedure described at the beginning of “The Original Problem” – which turns iterates of e(x) into iterates of exp(x) – to find iterates of exp(x), that is, to compute the fourth operation.
The resulting computer program is much simpler than “Computer Program I.” Here is a glossary translating the computer program functions into the mathematical functions we used in the first part of the previous section.
| Program | Analysis |
| eExp(s, x) | e s(x) |
| ExpInteger(n, x) | expn(x) |
| ExpReal(s, x) | exps(x) |
' The Fourth Operation II
'------------------------------------------------------------
Macro Precision = Double
Macro expRealTol = .0000001
Macro tol = .01
Global e As Precision 'constant
Global overflowflag As Long 'flag
'------------------------------------------------------------
Function eExp(ByVal s As Precision, ByVal x As Precision) As Precision
Local cnt, i As Long
Local ss, sss As Precision
Local y As Precision
' s has already been put in range by caller, 0 <= s < 1
Do Until x < tol 'drop x down to less than tol
x = Log(x + 1)
Incr cnt
Loop 'or else
Do Until x > -tol 'raise x up to greater than 0
x = Exp(x) - 1
Decr cnt
Loop
ss = s*s 's^2
sss = ss*s 's^3
y = x + _
(s/2) * x^2 + _
(-s/12 + ss/4) * x^3 + _
(s/48 - 5*ss/48 + sss/8) * x^4 + _
(-s/180 + ss/24 - 13*sss/144 + sss*s/16) * x^5
If cnt > 0 Then
For i = 1 To cnt
y = Exp(y) - 1
Next
ElseIf cnt < 0 Then
For i = 1 To -cnt
y = Log(y + 1)
Next
End If
Function = y
End Function
'------------------------------------------------------------
Function ExpInteger(ByVal n As Long, ByVal x As Precision) As Precision
Local i As Long
If n >= 0 Then
For i = 1 To n
x = Exp(x)
Next
Else
For i = 1 To -n
If x <= 0 Then
overflowflag = 2
Exit Function
End If
x = Log(x)
Next
End If
Function = x
End Function
'------------------------------------------------------------
' This is the main function.
Function ExpReal(ByVal s As Precision, ByVal x As Precision) As Precision
Local y, v, lasty As Precision
Local cnt, n As Long
cnt = Int(s) 'whole part of s
s = s - cnt 'fractional part of s, it is now 0 <= s < 1
' here 0 <= s < 1, cnt = integral part of original s
If s = 0 Then
overflowflag = 0
Function = ExpInteger(cnt, x)
Exit Function
End If
If x < 0 Then 'get 0 <= x < e
x = Exp(x)
Decr cnt
ElseIf x >= e Then
Do Until x < e
x = Log(x)
Incr cnt
Loop
End If
y = eExp(s, x) 'n = 0
lasty = y
n = 1
Do
overflowflag = 0
v = expInteger(-n, (eExp(s, expInteger(n, x))))
If overflowflag Then Exit Do 'use last y
y = v
If Abs(y - lasty) < expRealTol Then Exit Do 'Cauchy convergence
lasty = y
Incr n
Loop
Function = expInteger(cnt, y)
End Function
'===========================================================================
%list = 1
%socket = 2
%graph = 3
%which = %socket 'one of the above
%xd = 180 'used in the %graph case
%yf = 23
Function Main
Local w, h, a, b As Long
Local s As Precision
Desktop Get Size To w, h 'set up console window
Console Get Size To a, b
Console Set Loc (w - a)\2, (h - b)\2
Console Set Screen 120, 100
e = Exp(1) 'global constant
#If %which = %list '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Print " "; " s", " e sub s"
Print " "; "----------------------"
For s = -1 To 3.5 Step .125
Print " "; Format$(s,"* .000;-0.000"), Format$(ExpReal(s, 1)," #.00000")
Next
WaitKey$
#ElseIf %which = %socket '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Local x As Precision
Print " *** to exit, click X at upper right corner ***" :Print
Print " This demonstration doesn't check that s and x are within"
Print " bounds. It will give a nonsensical result if in the course"
Print " of the calculation the logarithm of a negative number would
Print " have to be performed or a number is computed that is larger
Print " than double precision can handle." :Print
Do
Input " Enter s operand: "; s
Input " Enter x socket: "; x
Print " exp sub"; s; "(";Format$(x,"#.0#####");") = "; Format$(ExpReal(s, x)," #.000000")
Print
Loop
#Else '%which = %graph '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Local i, c As Long
Local x, y As Precision
Local winC As Dword
Print " *** to exit, click on this window and press Esc ***" :Print
Graphic Window "", 100, 0, 768, 768 To winC 'set up graphic window
Graphic Attach winC, 0
Graphic Scale (-384,384+200) - (384,-384+200)
Sleep 1
For i = -9 To 29 'horizontal lines
If i = 0 Then c = %Black Else c = &hA0A0A0
Graphic Line (-384,i*%yf)-(384,i*%yf), c
Next
For i = -2 To 3 'vertical lines
If i = 0 Then c = %Black Else c = &hA0A0A0
Graphic Line (i*%xd,-384+200)-(i*%xd,384+200), c
Next
Graphic Width 2 'graph
x = -2*%xd + .000001
y = %yf*ExpReal(x/%xd, 1)
Graphic Set Pixel (x, y)
For x = -2*%xd + .000001 To 2.3*%xd
y = %yf*ExpReal(x/%xd, 1)
Graphic Line -(x,y), %Red
If InStat And InKey$ = $Esc Then Exit Function
Next
WaitKey$
#EndIf '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
End Function
'-----------------------------------------------------------------
Is it Unique?
The question of uniqueness bedevils attempts to define the fourth operation. We first showed that exp(x) – 1 has a continuum of iterates es(x) that is unique. Then we defined exps(x) in terms of es(x); however we did not prove it is unique.
Using a different approach Szekeres showed “by partly intuitive arguments” that since the Abel function of e(x), is “well-behaved” at infinity, it merits being used as a comparison function that determines a unique Abel function for any reasonable function. What recommends his idea of well-behaved is hard to follow.
Bases Other Than e
What if we wanted to know 2½ instead of e½? And in general bs for other bases? We can again use the “socket” idea and functional analysis: let f (x) = bx and find its functional iterates. Note that to ensure f (x) is real and continuous b must exceed zero.
We will try to develop functional iterates around a fixed point as we did before when b was e. Now in that case f (x) had no fixed point so we resorted to the artifice of first considering f (x) minus one. However for general b, in some cases we have a fixed point to begin with, in fact perhaps two; the number depends on what range of the real line b is in. We can determine them by examining the intersection of the graph of y = bx with the graph of y = x. The ranges break at zero, one, and the eth root of e.
| | range of b | # of fixed points of f (x) = bx |
| 1. | 0 < b ≤ 1 | 1 (the graph crosses y = x) |
| 2. | 1 < b < e1/e | 2 (it crosses y = x over and back) |
| 3. | b = e1/e | 1 (it is tangent) |
| 4. | b > e1/e | 0 (it is separate) |
If the first case, where f (x) has exactly one fixed point, we can use the fact (pointed out in the second footnote after the proof of Lemma #1 above) that for any function f (x) having a fixed point at x = a,f s ’(a) = (f ’(a)) s
That gives an extra term of our power series so we can find the other terms directly.
The second case is a problem. We could do at each point what was suggested in the first case but that would result in two different functional iterates of the given function. Another problem with having more than one fixed point is that then there could be no single Abel’s function. Recall that the Abel function A(x) must be defined for x > 0 andA(e(x)) = A(x) + 1
If for example f (x) = 2x – 1, which has a fixed point at zero and at one, then A(x) could not be defined at x = 1. The Abel function will always be singular at a fixed point. We will return to the second case in a moment.
The third case, where f ’(a) = 1, can be solved with the methods we used for f (x) = ex – 1, which has exactly one fixed point, at zero, and f ’(0) = 1. The details will be given when we examine the fourth case of which the third is a limiting case: as b approaches e1/e, the graph y = f (x) approaches just touching the graph of y = x.
The fourth case, like the second, is a problem. We shall try to solve it as well as the second by translating f (x) = bx so it just touches y = x, as we did with f (x) = ex.
Note that in the first and third cases no translation artifice is necessary, so the resulting fractional iterates are demonstrably unique, just as those of ex – 1 were.
We will use the same labels for the various functions as before. We need to define e(x) having a unique fixed point whose percentage difference with bx goes to zero (that is, their ratio goes to one) as x goes to infinity.
To accomplish that we shall translate the graph of y = bx vertically by an amount that makes it tangent to y = x. In general, unlike the case when b = e, the tangent point will not be at the origin. To simplify expressions, in what follows letr = log b
where as usual log is the natural logarithm. Note thatbx = e rx
and when b = e, r = 1.
Setting the derivative of y = bx to 1 (the slope of y = x) and solving for x gives x = – (log r) / r. Again to simplify future expressions letu = – (log r) / r
Note thatbu = 1/r
So the point (u, 1/r) on the graph of y = bx is where the slope is 1. Thus if we translate by – (1/r – u), lettinge(x) = bx – (1/r – u)
then e(u) = u and that is the only fixed point. The derivative ise’(x) = r bx
In the special case where the base b = e1/e, which is 1.44466786..., we have r = 1/e, u = e so that 1/r – u = 0, and no translation is necessary, y = bx itself has exactly one fixed point, at x = e. (This is the third case above, where the graph is tangent to that of y = x.) In this case, to repeat, the continuous iterates are demonstrably unique.
Let A(x) be an Abel function for the new e(x)A(e(x)) = A(x) + 1
and leta(x) = A’(x)
be the corresponding derived Abel function. Schröder’s equation for the new e(x) isΦ(e(x)) = r bx Φ(x)
As before we want to determine the Taylor series of Φ(x) but this time at x = u.Φ(x) ~ c0 + c1 (x – u) + c2 (x – u)2 + c3 (x – u)3 + ... as x → u+
Taking the first and second derivatives of each side of Schröder’s equation and evaluating at u we can, as before, eventually conclude that Φ’(u) = 0 and Φ’’(u) = 0, so that both c0 and c1 in the Taylor expansion are 0.Φ(x) ~ c2 (x – u)2 + c3 (x – u)3 + ... as x → u+
Again we need another coefficient and turn to finding the Taylor expansion of es(x), first in powers of (x – u) and then in powers of s.
As before we take the first derivative with respect to x of each side of es(x) = e(es–1(x)) and evaluate at u to eventually obtaines’(u) = es–1’(u)
and soes’(u) = et’(u)
where t is the fractional part of s. Thus as before es’(u) = 1 when s is a whole number and the same proof as before shows this is true for all real s.
Taking the derivative with respect to x again and evaluating at x = u eventually leads toes’’(u) = r + es–1’’(u)
so thates’’(u) = n r + et’’(u)
where n and t are the integral and fractional parts of s respectively. Thus when s is a whole number es’’(u) = s r and a similar proof as before shows this holds for all real s.
Thus the Taylor expansion begins:es(x) ~ (x – u) + 1/2 s r (x – u)2 + ... as x → u
Footnote
Determining the Taylor expansion of es(x) viewed as a function of s goes exactly as before and we havees(x) ~ x + Φ(x) s + c2 s2 + c3 s3 + ... as s → 0
We are trying to find Φ(x) . We proved that its Taylor expansion beginsΦ(x) ~ c2 (x – u) 2 + c3 (x – u) 3 + c4 (x – u) 4 + ... as x → u+
and if, as before, we know just c2 we can determine the others. An argument similar to the one before shows that the second-order coefficient in the power expansion of Φ(x) is ½ r.Thus we haveΦ(x) = 1/2
r
(x – u)
2 +
c
3 (x – u)
3 +
c
4 (x – u)
4 +
... as x → u
+
Now we use Schröder’s equation to determine the other coefficients. Schröder’s equation isΦ(e(x)) = r bx Φ(x)
orΦ(erx – 1/r + u) = r er x Φ(x)
Substituting in the power series as we did before when b = e we can deduce thatc3 = (1/48 u2 r4 – 1/6 u r3 + 7/24 r2 – 1/3 r3)
/ (27/8 r2 – 2 r – 7/8 +1/24 u3 r3 + 1/2 u2 r2 + 3/2 u r)
and succeeding coefficients can be computed likewise. If b = e then r = 1 and u = 0; and c3 reduces to – 1/12 and c4 to 1/48, the values we found before. When b = 2, c3 = – .053891092257005... and c4 = .00280571012920368... .
Repeated application ofe-1(x) = logarithm to base b of (x– u + 1/r) = (1/r) log (x – u + 1/r)
will reduce any x > u to as close to u as desired. Given x0 > u, let xi = e-i(x0), then using Schröder’s equation as before we can eventually concludeΦ(x0) = rn (x0 + v) (x1 + v) ... (xn-1 + v) Φ(xn)
where v = 1/r – u. Since u might exceed zero we also need to consider the case x0 < u. Repeated application of e(x) will increase x0 to as close to u as desired. Let xi = ei(x0), thenΦ(x0) = Φ(xn) / rn(x1 + v)(x2 + v) ... (xn + v)
Thus we have Φ(x) and consequently A(x) and the continuous iterates of e(x). We can get from continuous iterates of e(x) to those of bx by the same method as before except that exp and log are replaced with exp and log to the base b.
In the special case b = e1/e this last step is unnecessary because then e(x) = bx. In that case, the third case above, to repeat, the iterates are unique. When 0 < b ≤ 1 there is also exactly one fixed point and again the continuous iterates are unique. Furthermore, the graph of y = bx is not tangent to the graph of y = x so they are much easier to compute.
Review and a Glance at the Complex Plane
We sought to define e raised to itself s times where s can be fractional. We added a sort of “socket” variable to turn the problem into defining continuous iterates of the function exp(x).
Since finding a unique continuous iterate of a function that has no fixed point, such as exp(x), is difficult, instead we considered the function exp(x) – 1, which has exactly one fixed point. Following George Szekeres (1911 – 2005) and patching up gaps in his work, we found by an intricate argument assuming only smoothness, a unique solution for the continuous iterates of that function.
Then we used it to find a solution for the continuous iterates of exp(x). However its uniqueness is a problem.
So far all we have used is real analysis. Another way to get around the fact that exp(x) has no fixed point is to go into the complex plane to find one, that is, consider exp(z) where z varies over the complex numbers. The trouble is that exp(z) has more than one fixed point, indeed an infinite number, and that leads to singularities and non-uniqueness. There are ways of dealing with the singularities but to get uniqueness requires further conditions. Hellmuth Kneser (1898 – 1973) chose one fixed point to construct an analytic solution, and later other people improved on his work. As for numerical results, Kneser’s solution differs from the one obtained by the Φ(x) approach. For example, e½ is 1.64515… per our calculation whereas it is 1.64635… per Kneser’s.
There are many Kneser’s iterations, one for each fixed point. Ultimately the choice is arbitrary – one fixed point is like another – so Kneser’s primary iteration is not unique. Conditions can be posited to make a particular fixed point special but are they reasonable conditions?
At any rate, even if we failed with exp(x), the continuous iteration of e(x) = exp(x) – 1, solved here for the first time without arbitrary assumptions, is interesting in its own right.
Footnote
Szekeres was interested in continuously iterating e(x) in order to interpolate G. H. Hardy’s logarithmico-exponential scale. A(x), its Abel function, grows more slowly than any finite iteration of log(x) and the inverse grows more rapidly than any finite iteration of exp(x), thus these two functions are respectively below and above Hardy’s scale. (Note that Szekeres more than once mistakenly refers to a(x), the derived Abel function, when he means A(x).)
A Zeroth Operation?
In the introduction we took addition to be the first and basic operation. Some people have tried to define a zero’th operation before addition, called “succession.” It is a unary operation that increments its operand. Then iterating it on A, B times, would add B to A.
There are several problems with this zero’th operation. It is not a binary operation like the other operations. And since incrementing is a particular case of addition, it isn’t as different as a new operation should be.
A third problem involves this curious sequence:2 + 2 = 4
2
· 2
= 4
2
2 =
4
A [n] (B + 1) = A
[n – 1]
(
A [n] B
)
2 [n] 2 = 2
[n – 1]
(
2 [n] 1
)
We could make, rather artificially, succession a binary operation by having it increment one of the two operands and ignore the other (for the recursion formula given in the introduction to work it would have to increment the second operand), but then the “2 on 2 theorem” would fail:The 2 on 2 theorem is a nice little theorem. That it doesn’t hold for [0] suggests that [0] is illegitimate.
For all these reasons, the bottom operation should be addition, [1], rather than succession.
There is no zero’th operation.
While we’re on the subject of the specialness of addition, note that its “unit” – the number for the second operand that doesn’t affect the first – is zero. For any A:Whereas with the operations beyond addition, n > 1, the unit is one:It is also interesting to note that for operations beyond multiplication, n > 2:which follows from the recursion formula given in the introduction. When n = 1 or 2 (addition or multiplication) the result is A or 0 respectively. (Not only are addition and multiplication different from each other, this change after multiplication suggests that the two are fundamentally different than exponentiation when we try to make them the beginning of a series, a subject we will return to in the last section.)
Other Terminology and Notation
The fourth operation is known by various names: tetration, super-exponentiation, hyperpowers, power towers.
Instead of the subscript notation es some authors use the pre-superscript notation se (Hans Maurer (1868 – 1945) used it in a paper of 1901). Other notations, which generalize to operations of other order, are H4(e, s), and Donald Knuth’s arrow notation e ↑↑ s (the number of arrows, two less than what you would expect, is confusing).
Given X = bp the inverse operation giving b has been called the super-root, denoted by srt p X. The inverse operation giving p has been called the super-logarithm, denoted by slog b X. (Rarely, “tetra” has been used instead of “super” while retaining the slog and srt notation.)
Afterword
A case can be made that there is no sequence of operations as presented in our introduction, that there are only two binary operations, addition and multiplication; that exponentiation is not a binary operation but a function of a single variable (the exponent) with a parameter (the base). Its purpose is to turn addition into multiplication; it is a go-between for two binary operations but not a binary operation itself.
Exponentiation stands out from addition and multiplication because unlike them it cannot be defined (in the real domain) for all numbers. When the base is negative the exponent must be integral. (Thus when the base is negative the exponent cannot vary continuously.)
Even restricted to nonnegative numbers, exponentiation stands out because it is non-associative. It is not a group operation like addition and multiplication.
Another reason exponentiation stands out is that it has no geometric construction that is continuous in the exponent. Addition can be thought of as laying two line segments end to end in a straight line, multiplication as the area indicated when line segments are joined perpendicularly. We run into a problem with exponentiation. X, X squared, X cubed, etc. make sense geometrically – a line segment, square, cube, and so forth in higher dimensions – but there is no continuum of dimensions to make sense of X raised to a fraction. What, for example, is between a square and a cube? (The fractional and continuous geometries of Menger, Birkoff, and von Neumann are no help because their dimensions range between zero and one, and they are projective geometries not Euclidean.)
A further difference – and it is among all three of addition, multiplication, and exponentiation – becomes apparent when using the operations to solve practical problems. In practice many numbers are not pure numbers but quantities, that is, they measure something in a certain unit such as meters or kilograms. We will say a pure number has the “null unit” so that all numbers have units. When adding two numbers both must be in the same unit. As the saying goes, “You can’t add apples and oranges.” When multiplying there is no such restriction, each number can have any unit. When neither number is pure the result is in a new unit. For example, two meters times three meters is six square meters, two watts times three hours is six watt-hours.
Multiplication can be considered repeated addition only when one of the numbers – the number measuring the repetition – is pure. Adding five apples to itself three times makes 15 apples, but using three apples or three oranges as a count for adding makes no sense. A count must be a pure number.
Thus with exponentiation, the exponent must be pure. (An exponent might be an expression involving quantities but when evaluated the units must cancel.) And if the exponent can vary continuously the base must be pure as well. In general there is no exponentiation of quantities.
With what we have called the fourth operation, both base and “super-exponent” must be pure. (We could except the trivial cases where the super-exponent is 0 or 1, resulting in 1 or the base respectively.) This suggests that this so-called operation can have no practical application beyond generating large pure numbers, and in that case only whole number iterates would be needed.
Thus it would seem we have gone on a fool’s errand, though an interesting one. Not only is there no fourth operation, there is not even a third operation. Exponentiation, to repeat, should not be viewed as a third binary operation or as any kind of binary operation. It is a function on pure numbers, or rather a continuum of functions parameterized by a base. It is a bridge between the addtion and subtraction of unitless numbers, converting addition to multiplication and whose inverse converts multiplication to addition.
Simple fractional (rational) exponents are useful in physics, in which sase the denominator indicates a root. In mathematics, when trying to describe the growth of a function as a variable goes to infinity, a real (even transcendental) exponent can be useful.